
Moving an object in a single image requires geometry-consistent spatial rearrangement, including handling occlusions, revealing previously unseen regions, and maintaining coherent shadows and reflections. Existing approaches are not well suited to this setting and often fail to preserve such scene-level consistency.
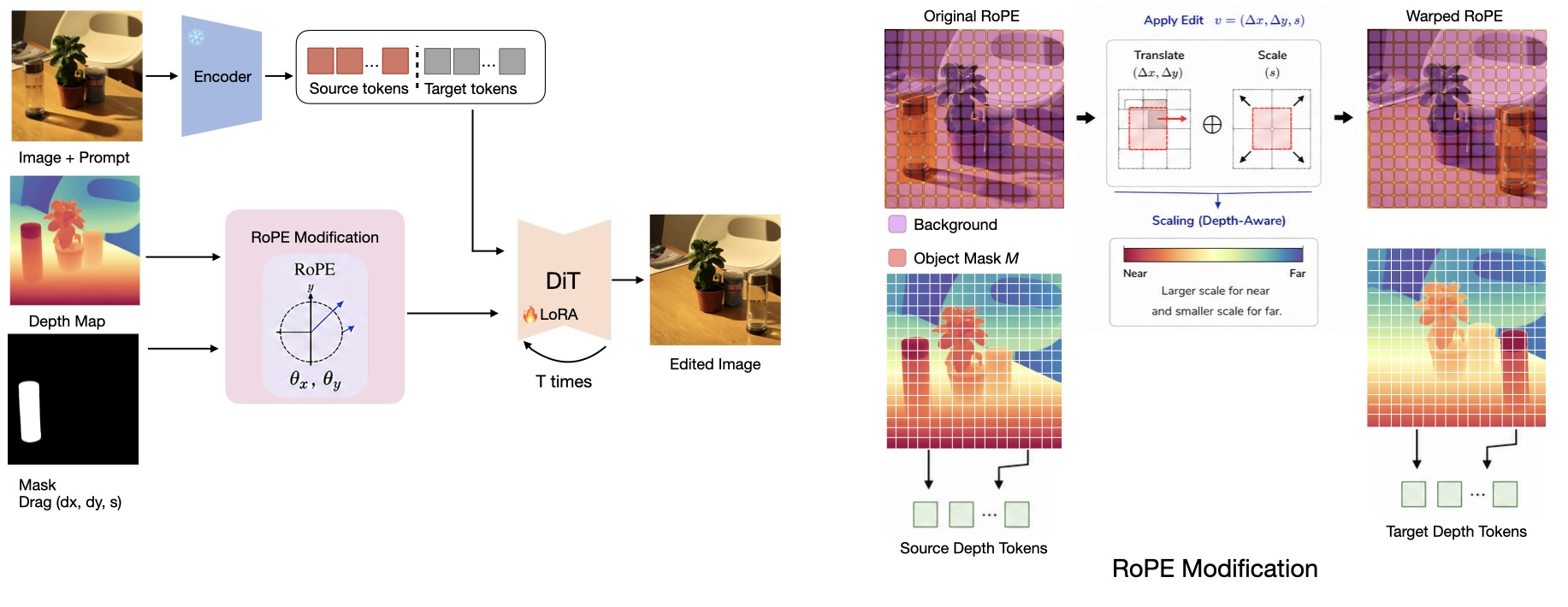
We address this problem by introducing a geometry-aware object motion method that operates directly on the positional representations of diffusion transformers. Our key insight is that rotary positional embeddings (RoPE) define a structured spatial field that can be explicitly manipulated to induce controlled motion. We extend 2D RoPE into a depth-aware formulation that encodes 3D spatial structure, enabling consistent object displacement and scene-aware updates.
Our model is trained using synthetic data combined with a small set of real images via parameter-efficient fine-tuning. Despite minimal real supervision, it preserves object identity under large spatial displacements, generates plausible content in newly revealed regions, and consistently updates scene-dependent effects such as shadows and illumination.
Experimental results on standard object motion benchmarks demonstrate state-of-the-art performance across all evaluation metrics.
Watch RoPEMover in action: starting from a single image, a user paints an object mask, drags it to a new target location, and the depth-aware RoPE-warped diffusion transformer renders the edited scene — handling occlusions, shadows, and newly revealed background regions automatically.
End-to-end demonstration of the RoPEMover pipeline: object selection, drag target placement, and depth-aware diffusion synthesis.
We compare RoPEMover against 11 baselines on the ObjMove-A benchmark. Switch tabs to inspect different qualitative slices or the headline quantitative numbers.

Qualitative comparisons against MagicFixUp, FreeFine, Inpaint4Drag, GeoDiffuser, Qwen-Image, FLUX Kontext, and Object Mover on ObjMove-A.

Additional qualitative comparisons — Set A.

Additional qualitative comparisons — Set B.
| Method | CLIP Score ↑ | DINO Score ↑ | DreamSim ↓ | PSNR (dB) ↑ | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Tgt | BG | Src | Tgt | BG | Src | Tgt | BG | Src | ||
| ChronoEdit | 73.27 | 92.93 | 77.65 | 45.27 | 91.17 | 44.28 | 0.6261 | 0.1026 | 0.5896 | 20.49 |
| 3DiT | 75.74 | 91.08 | 83.24 | 48.78 | 86.81 | 48.21 | 0.5723 | 0.1711 | 0.4934 | 18.59 |
| DragAnything | 76.51 | 82.26 | 84.28 | 48.85 | 66.69 | 36.21 | 0.4460 | 0.3681 | 0.5233 | 11.21 |
| DragDiffusion | 74.40 | 91.35 | 80.00 | 46.51 | 86.97 | 46.93 | 0.6237 | 0.1369 | 0.5741 | 19.56 |
| Inpaint4Drag | 92.08 | 96.49 | 83.46 | 85.09 | 95.10 | 55.54 | 0.1379 | 0.0632 | 0.4798 | 22.85 |
| MagicFixup | 89.62 | 96.06 | 92.60 | 80.90 | 95.29 | 78.49 | 0.1755 | 0.0552 | 0.1853 | 23.32 |
| GeoDiffuser | 76.13 | 93.76 | 86.64 | 53.18 | 91.88 | 59.73 | 0.5430 | 0.0987 | 0.4109 | 19.65 |
| Qwen-Image | 81.23 | 94.01 | 81.23 | 64.14 | 92.12 | 56.78 | 0.4132 | 0.1003 | 0.4719 | 19.04 |
| FLUX Kontext | 76.26 | 94.80 | 78.86 | 51.26 | 92.58 | 50.05 | 0.5719 | 0.1068 | 0.5402 | 19.21 |
| FreeFine | 90.26 | 96.09 | 91.33 | 82.11 | 94.91 | 71.30 | 0.1611 | 0.0564 | 0.2421 | 22.81 |
| Object Mover | 85.32 | 96.61 | 88.61 | 80.08 | 96.21 | 77.46 | 0.1849 | 0.0449 | 0.1895 | 24.06 |
| Ours | 91.74 | 97.59 | 94.67 | 87.40 | 97.57 | 87.37 | 0.1180 | 0.0292 | 0.1012 | 24.97 |
Comparison on the ObjMove-A benchmark. Bold = best, underline = second best. Higher-is-better for CLIP / DINO / PSNR; lower-is-better for DreamSim.
We ablate the two key contributions of RoPEMover: the depth-aware RoPE warp, and the two-stage training pipeline (synthetic → real fine-tuning).

Architectural ablation. Starting from a pretrained Qwen-Image edit baseline, we progressively add (i) LoRA fine-tuning, (ii) RoPE-based spatial warping, and (iii) depth-aware 3D RoPE. Each step yields measurable gains in spatial control and identity preservation.

Two-stage training. The Stage 1 model (synthetic-only) reliably relocates objects but loses fine appearance details. Stage 2 fine-tuning on a small captured real-image set restores identity and even relocates secondary effects like reflections.


@article{oztas2026ropemover,
title = {RoPEMover: Depth-Aware Object Relocation via Positional Embeddings},
author = {Oztas, Ipek and Ceylan, Duygu and Aksoy, Aybars Bugra and Dundar, Aysegul},
journal = {arXiv preprint},
year = {2026}
}